is a blog about design, technology and culture written by Khoi Vinh, and has been more or less continuously published since December 2000 in New York City. Khoi is currently Principal Designer at Adobe. Previously, Khoi was co-founder and CEO of Mixel (acquired in 2013), Design Director of The New York Times Online, and co-founder of the design studio Behavior, LLC. He is the author of “How They Got There: Interviews with Digital Designers About Their Careers”and “Ordering Disorder: Grid Principles for Web Design,” and was named one of Fast Company’s “fifty most influential designers in America.” Khoi lives in Crown Heights, Brooklyn with his wife and three children.
Of the major technological shifts that designers are all constantly being told we need to prepare for, the idea of voice assistants becoming a major method for interacting with computers fascinates me most, in no small part because it seems the most inevitable. Whether or not we’ll soon all be wearing augmented reality glasses or immersing ourselves in virtual reality spaces for hours at a time, it’s easy to imagine a role for a voice-based interface like Alexa, Google Assistant or Siri in these new experiences, not to mention in plain old real life. We are at the very beginning of this phenomenon, though, and the tools for creating applications on these platforms are still primitive.
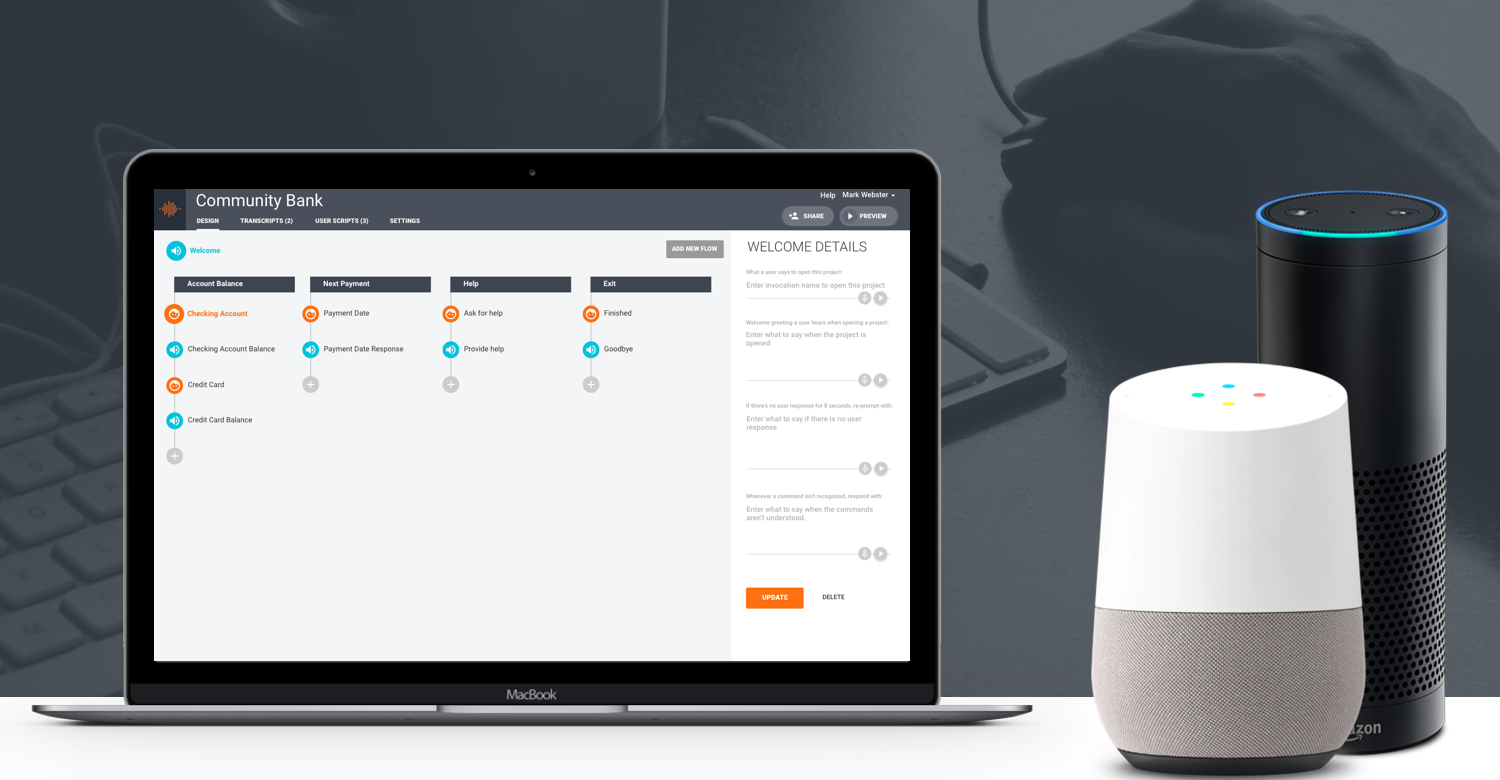
That’s why I was so impressed when I saw Sayspring for the first time earlier this year. While there are plenty of development tools for voice out there, Sayspring is the first I’ve seen that treats voice user interfaces explicitly as a design problem, which immediately struck me as exactly right. The app allows even those with no prior experience in voice UIs or bots to get a prototype Alexa skill or Google Assistant service up and running within minutes—on an actual Echo or a Home, no less. More than just technically impressive, that fast track ability quickly makes it clear that the experience of a voice app requires lots of iteration, careful trial and error—in other words, design. Of course, thinking about voice UIs in this design-centric way raises all kinds of questions about how this technology can evolve into a language (no pun intended) that resonates with users. So I interviewed Sayspring founder and CEO Mark Webster about his ambitions for Sayspring and his thoughts on voice assistants in general.
Khoi Vinh: What makes Sayspring different and better than the development kits that Amazon and Google provide?
Mark Webster: As you mention, both Amazon and Google have been focused on releasing code templates and tutorials to help developers quickly build simple apps, like quizzes and fact generators. This has been great to help everyone get their feet wet with these platforms, but it has also resulted in some lame voice apps. While these platforms are new, so are voice interfaces themselves. Product teams don’t have much experience with them. What’s needed to fulfill the promise of this powerful new medium is not a focus on how to build for voice, but what are we building, why are we building it, and who is it for?
Answering those questions requires making design a part of the process, and doing that requires a set of tools that removes all the technical barriers to working with voice. That’s what Sayspring does. Our collaborative design software lets designers, UX professionals, and product people craft voice-powered user experiences, and actually talk to them in real-time, without needing to code or deploy anything.
Our belief is that great voice experiences start with focusing on the user journey, and that is how the process of designing and prototyping on Sayspring begins. You don’t need to know anything about the underlying technology of voice to use Sayspring. You just plan out the flows of the experience, add some commands and responses, and start talking to your project on any device. You can even share it with others, to do user testing prior to development.
The best companies understand the value of a proper design process across web and mobile. Sayspring is bringing that disciplined approach to voice. Over time, we’ll make it easier for every person in the organization to work with voice apps, from design to development to production. But I strongly believe that if you begin product creation with a weak design approach, everything that comes after it is a waste of time so that’s why we’re starting there.
The design and prototyping approach kind of upends what everyone expects from a voice UI tool at this stage in the evolution of voice UIs: that they should help you deploy a completed product as well. How important—or unimportant—is that to Sayspring, now and in the near future?
Let’s take a look at where we are in the current evolution of voice UIs. When it comes to voice applications, Alexa alone already has over 11,000 Alexa Skills, so the deploying of completed products is continually happening. The process could definitely be easier, but developers are figuring it out. But many of these applications are underwhelming and quickly abandoned.
Every disruptive medium has an early period where creators take something from an earlier medium and just move it to the new one. The first television shows were radio shows in front of a camera, the first mobile apps were just smaller versions of websites. It takes some time to understand the nuances and power of a new medium, to create the experiences that fully leverage the possibilities available.
For voice, we’re trying to push the process forward by empowering designers to work in this new medium in a way that’s impossible without Sayspring.
We’re at the dawn of a massive shift in computing, unlike what we’ve seen in the past. Voice promises to deliver interactions closer to how we all communicate as human beings. Applications have to adapt to people now, instead of the other way around. There is no mouse or keyboard or screen to learn how to use. We all know how to speak to one another, and voice applications have to conform to that. This is maybe the biggest design challenge we’ve seen in the digital world.
One huge advantage to working with voice UIs over visual UIs is that they’re ultimately text-based, so the division between design and development is more blurred than it traditionally has been in the past. This means that once you’ve completed the design process, moving into development and deploying is relatively straightforward and Sayspring will be able to do a lot of the heavy-lifting to bring that product to production. Our mission is to become the one place where a team can design, build, and manage their voice applications across multiple voice platforms. So we plan to handle the end-to-end process of creation, but first we all collectively need to focus on designing experiences worth shipping.
Do you believe that voice UIs will continue to be “ultimately text-based,” as you say? I’m thinking about Apple’s CarPlay, Google’s Android Auto and obviously Amazon’s recently announced Echo Look. These seem to suggest that voice and screen can be an effective combination.
I meant that the output of the voice design process—intents, utterances, entities, the actual speech—is ultimately text-based, so from a workflow standpoint, moving from design to development tends to be more seamless.
Many voice-driven experiences will involve a screen though, in addition to voice simply being a method of input for a traditional GUI-based experience. We’re already working on display support for Sayspring. The visual components for Alexa and Google Home are currently restricted to text and one image, so it’s easy to implement. As they get more involved, Sayspring would integrate with other tools like Photoshop or Sketch, to handle the visual aspect. I can’t see Sayspring ever trying to rebuild the popular products we already have for visual design.
We think a lot about the multi-modality of voice and screens. One thought exercise we often use is to imagine an assistant following you at all times with a laptop they’d use to perform the tasks you ask for. You could have a conversation to get things done, and at certain moments it would make sense for them to turn the laptop around and show you the screen.
So you might tell them you want to see a Broadway show this weekend, and have a dialog about what kind of show you’re interested in, what you’ve already seen, and what’s available. If you decide to buy tickets, they would likely want to show you a seat map of the theater on the screen. You’d tell them what tickets to buy, and they’d finish the transaction. That’s the way ticket purchasing through a VUI would likely happen as well.
I imagine that kind of metaphor or mental model is helpful for imagining what a voice-based user experience can be, since the form is relatively new. How much do you think it’s Sayspring’s job to help your users grok the unique challenges of designing in this medium?
Considering how new this medium is to most people, we feel a huge responsibility to both our users and to the design community as a whole. We’re not only helping people work through the process of voice design, we’re also out there advocating that voice experiences need to be designed in the first place. Too many voice applications are being created by developers with no design input, and most companies working with voice have yet to establish a proper design process. We see ourselves as advocates for design within the broader conversation about voice.
Helping designers work with a new medium also brings with it some product challenges for our team. To give you one example, personality design is a crucial part of the voice design process. Beyond just selecting the words to use, speech can be styled with SSML (Speech Synthesis Markup Language) to add pauses, change the pronunciation of words, and include certain tone or inflection changes.
SSML looks similar to HTML, and we’re considering adding a rich-text editor for SSML to Sayspring. Now, there aren’t many designers out there asking for better SSML tools, and it doesn’t come up in user feedback. But do we put it out in the world anyway, with the belief that it will help users create better voice experiences? How opinionated should we be in steering the establishment of voice design practices? Or should we just be responsive to a more organic evolution? It’s a tough question to answer for us, and we think about that balance each time we prioritize our own product roadmap.
These kinds of considerations really suggest that this is an entirely different kind of design. Do you have a sense yet what makes for a good voice designer? And where is the overlap with what makes for a good visual interface designer?
While it’s going to be a new kind of design for many designers, it should still be based on the design process most of us are familiar with. All design work, including voice, should follow the fundamentals of defining the problem, doing research, brainstorming ideas, designing solutions, collecting feedback, and iterating. Ultimately what will make a good voice designer will be people who are thoughtful and process-driven in their visual design work, bringing that over to voice.
Sayspring wants to be the canvas where designers work with a medium that’s new to them, that is based on the process they already know and is inspired by the tools they’ve used before, but created specifically for voice. We view this new form of voice design as a remix of several disciplines that all have a long history to borrow from. Designing for phone-based interactive voice response (IVR) systems involves crafting a voice-driven user journey. Copywriting and screenwriting focus on word selection, delivery of message, narrative, and personality. And sound design or voice-over work has a lot to say about pacing, inflection, tone of language, and auditory atmosphere.
We’ll also eventually have multiple designers, with specific specialties, all working together on voice projects. Including sound design is a great example actually. Most creators of Alexa Skills or Google Assistant Actions have yet to explore using non-verbal audio as part of the experience. For example, “earcons” are short, distinct sounds that can be used to landmark a user to where they are in the application, almost like using varying header colors to identify sections of a website. Almost no one is using them. Nearly every Skill lets you know you’ve opened it by saying “Welcome to Skill Name” instead of playing a short, familiar audio clip. That will change over time.
I think we’ll soon see the design of voice application involve an interaction designer to construct it, a copywriter to write the actual speech, and a sound designer adding enhancements, cues, and atmosphere to the experience. And we want that all to happen in Sayspring.
Do you think that having more diversely skilled teams and richer workflows is what’s needed to help these Alexa Skills and Google Assistant Actions get to the next level? By some estimates, the vast majority of these apps go unused–they’re hard for new users to discover and even if a user installs one of them, the chances that she’ll be using it again in week two or week three are vanishingly small. Aside from Spotify, I’m not sure there’s another app that has broken through in a serious way.
I think smarter teams gaining a deeper understanding of how to use this new medium, along with platform improvements (like changes to discovery), will drive the shift to voice.
Alexa knowing more about you is important to fix discovery. For example, music is an ideal use case for voice interfaces, but the option to connect to Spotify then never having to ask for Spotify again helped. We’re seeing more and more of this happen. Alexa just released a new video API to connect to cable boxes and streaming services that doesn’t require the specific invocation of the skill or app. Dish already launched this type of skill for Alexa, so now saying “Alexa, go to ESPN” changes the channel on your TV. That will help repeat usage tremendously. But they also need to make sure that skill is well-designed and easy to use.
Many early skills are starting points. Domino’s pizza launched an Alexa Skill, which allows you to reorder a pizza you’ve ordered before. Domino’s CEO Patrick Doyle has said the growing use of that skill has convinced the company to devote more resources towards the voice ordering experience. They’re working on being able to create an order from scratch now. With different sizes, toppings, deals, and sides, that’s a much harder design problem, and requires a more thoughtful design process.
But also, the shift to voice is bigger than just Skills and Actions. Google Analytics just announced voice support, on mobile and desktop, so you can ask “How many visitors did we have last week?” instead of fiddling with an interface. And twenty-five of all desktop Cortana queries on Windows 10 are voice. With 100 million active monthly Cortana users, that’s a lot of people already talking to their desktop computer. Designing voice interfaces will soon be a required task for any digital product design team.
I appreciate that a pizza order is more involved than playing music, but I wonder about the limits of voice UIs in terms of dealing with complex tasks of any real scale. In my personal experience, even the cognitive load of playing music is more than I would’ve expected. Unless I have a really, really specific idea of what I want to hear, I have to keep this catalog of music and artists that I like in my head, and that means I tend to play the same few things over and over. Yet when I look at iTunes, for better or worse, I can happen across all kinds of stuff that I wouldn’t be able to recall standing there in my kitchen, talking to Alexa or Google Home. Is there a practical limit to what these voice interfaces can do? Without an accompanying visual UI, that is?
Every medium has different strengths and weaknesses, and designers need to keep pushing the perceived limits of that medium to find solutions that users find valuable. For example, a lot of Alexa users deal with the issue of music discovery you mention, so last week Amazon Music launched support for over 500 activity requests like “pop music for cooking” or “classical music for sleeping” to help address it. I will say though that having spent a chunk of my career in streaming media, discovery is its own beast and definitely wouldn’t be solved just by adding a screen. I mean, the whole reason Pandora exists is to help you find something to listen to, regardless of the interface.
I wouldn’t think of voice interfaces in terms of having a practical limit, but rather back to this idea of its strengths and weaknesses. Everything shouldn’t be crammed into a voice-only experience. Something like browsing Pinterest wouldn’t work without a screen. Getting ideas for redesigning your kitchen requires a visual display. However, sitting on your couch, watching the TV screen and using a voice interface to ask for ideas, make suggestions, and browse through photos of kitchen concepts, glass of wine in hand, sounds delightful.
That does sound kind of delightful–but maybe just because of the glass of wine? All kidding aside, I think what you mean is that voice represents a much more casual, laid back approach to computing, is that right? And that we probably shouldn’t look to voice for major productivity?
It doesn’t feel either/or to me. It’s a more responsive form of computing, which offers entirely new opportunities for user-centric design. If I walk into my house, and want to turn on some lights and music with ease, voice is a great interface to deliver on that. If I’m a pharma sales rep who is driving between appointments and want to update my Salesforce records, instead of having to do them at the office later, voice serves that situation well too. Either way, it’s going to be fun to get our hands dirty figuring it out. And with seventy percent of the market right now, Alexa is great place to start designing for voice.
Last question: would you care to wager who will win this race, Alexa, Siri, Google Assistant, Cortana, other?
Overall, I think different platforms win different spaces. Alexa might take the home, Cortana might win the enterprise, Google Assistant or Siri could win the car. But it’s fair to say that if you’re competing directly with Amazon, on anything, you should be worried.